
오늘은 네이버 번역 API인 파파고를 사용해보겠습니다.
개발환경은 IntelliJ IDEA 2023.2.4 / Java 11 / SpringBoot 2.7.17 / React / Gradle / Oracle 11g 입니다.
기본적인 세팅이 되어있다는 가정 하에 API 사용하는 부분만 보여드리겠습니다.
📝 API KEY 발급받기
NAVER Developers
네이버 오픈 API들을 활용해 개발자들이 다양한 애플리케이션을 개발할 수 있도록 API 가이드와 SDK를 제공합니다. 제공중인 오픈 API에는 네이버 로그인, 검색, 단축URL, 캡차를 비롯 기계번역, 음
developers.naver.com
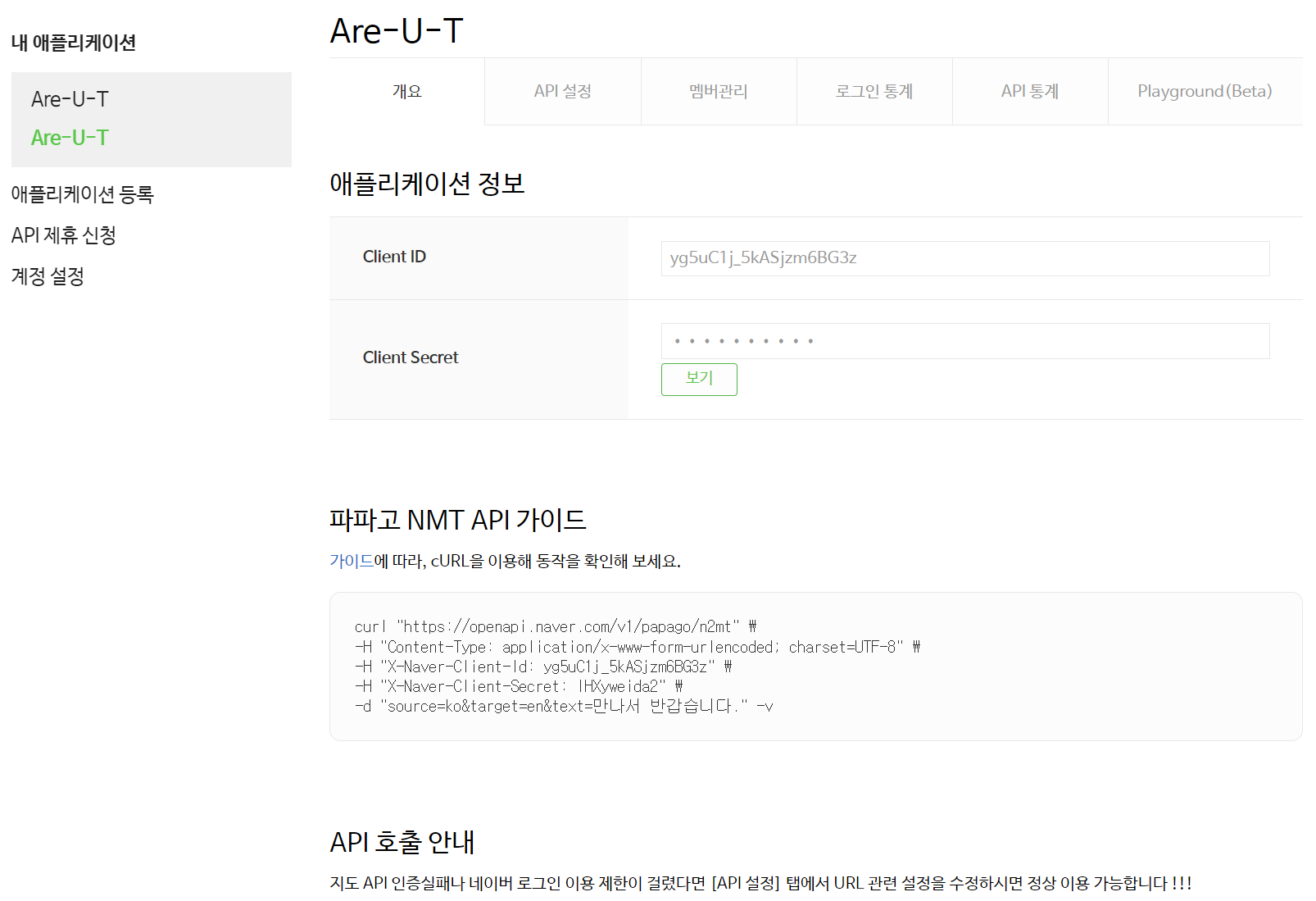
위 사이트에 들어가서 로그인 후 사용할 API 키를 발급 받습니다.
✔️ Application > 내 애플리케이션

✔️ 애플리케이션 등록

✔️ 이름, 사용할 API, URL 설정 > 등록하기

✔️ 내 어플리케이션에서 발급받은 키 확인 가능
📝 컨트롤러, 서비스 클래스 코드
저는 포스트맨으로 테스트를 할 거라 프론트 코드는 작성하지 않겠습니다.
✔️ 파파고 컨트롤러 생성
프론트에서 매개변수로 search라는 텍스트를 받을 겁니다.
search는 파파고로 번역할 텍스트입니다.
예를들어 프론트에서 넘긴 search 값이 "사과"이면 사과라는 단어를 번역하는 거죠.
💡 Controller
@CrossOrigin(origins = "httpL//localhost:3000")
@RestController
@RequestMapping("/api")
public class PapagoController {
public Logger logger = LoggerFactory.getLogger(NaverPapagoService.class);
@Autowired
NaverPapagoService naverPapagoService;
@PostMapping("/papago")
public String papagoAPI(@RequestBody String search) {
logger.info("***** *****");
logger.info("papago 사용 전 text: {}", search);
naverPapagoService.getTransSentence(search);
logger.info("***** *****");
logger.info("papago 사용 후 response: {}", naverPapagoService.getTransSentence(search));
return naverPapagoService.getTransSentence(search);
}
}
✔️ 파파고 서비스 생성
💡 Service
서비스는 컨트롤러와 마찬가지로 한 개의 매개변수를 받습니다. (String search)
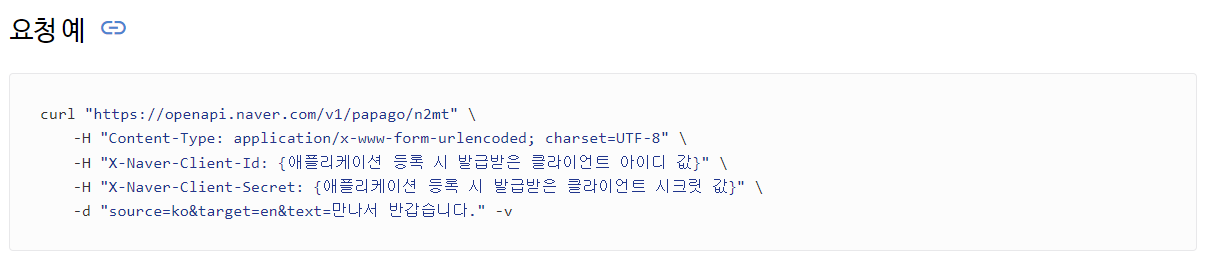
인코딩된 검색 텍스트를 저장하는 변수, 네이버 API ID, PW, API 엔드포인트를 선업합니다.
이 부분은 API 공식 문서에서 확인할 수 있습니다.
Papago 번역 API 레퍼런스 - Papago API
Papago 번역 API 레퍼런스 인공 신경망 기반 기계 번역 설명 인공 신경망 기반의 기계 번역(NMT, Neural Machine Translation) 결과를 반환합니다. 요청 URL https://openapi.naver.com/v1/papago/n2mt 프로토콜 HTTPS HTTP 메
developers.naver.com
String textContent;
String clientId = "";
String clientSecret = "";
String apiURL = "https://openapi.naver.com/v1/papago/n2mt";
public String getTransSentence(String search) {
String textContent;
String clientId = "";
String clientSecret = "";
String apiURL = "https://openapi.naver.com/v1/papago/n2mt";
try {
textContent = URLEncoder.encode(search, "UTF-8");
} catch (UnsupportedEncodingException e) {
throw new RuntimeException("papago API 인코딩 에러" + e);
}
Map<String, String> requestHeader = new HashMap<>();
requestHeader.put("X-Naver-Client-Id", clientId);
requestHeader.put("X-Naver-Client-Secret", clientSecret);
String resonseBody = post(apiURL, requestHeader, textContent);
logger.info("responseBody = {}", resonseBody);
return convertToData(resonseBody);
}
저는 쌍따옴표(")를 제외하고 DB에 저장할 거라 replace를 사용해 따옴표를 제거했습니다.
private String convertToData(String responseBody) {
try {
ObjectMapper objectMapper = new ObjectMapper();
JsonNode jsonNode = objectMapper.readTree(responseBody);
JsonNode resultNode = jsonNode.get("message").get("result");
String translatedText = resultNode.get("translatedText").asText();
translatedText = translatedText.replace("\"", "");
return translatedText;
} catch (Exception e) {
throw new RuntimeException("API 응답 데이터를 처리하는데 실패했습니다.", e);
}
}
private String post(String apiUrl, Map<String, String> requestHeaders, String text) {
HttpURLConnection con = connect(apiUrl);
String postParams = "source=ko&target=en&text=" + text;
try {
con.setRequestMethod("POST");
for (Map.Entry<String, String> header : requestHeaders.entrySet()) {
con.setRequestProperty(header.getKey(), header.getValue());
}
con.setDoOutput(true);
try (DataOutputStream wr = new DataOutputStream(con.getOutputStream())) {
wr.write(postParams.getBytes());
wr.flush();
}
int responseCode = con.getResponseCode();
if (responseCode == HttpURLConnection.HTTP_OK) {
return readBody(con.getInputStream());
} else {
return readBody(con.getErrorStream());
}
} catch (IOException e) {
throw new RuntimeException("API 요청과 응답 실패", e);
} finally {
con.disconnect();
}
}
private HttpURLConnection connect(String apiUrl) {
try {
URL url = new URL(apiUrl);
return (HttpURLConnection) url.openConnection();
} catch (MalformedURLException e) {
throw new RuntimeException("API URL이 잘못되었습니다. : " + apiUrl, e);
} catch (IOException e) {
throw new RuntimeException("연결이 실패했습니다. : " + apiUrl, e);
}
}
private String readBody(InputStream body) {
InputStreamReader streamReader = new InputStreamReader(body);
try (BufferedReader lineReader = new BufferedReader(streamReader)) {
StringBuilder responseBody = new StringBuilder();
String line;
while ((line = lineReader.readLine()) != null) {
responseBody.append(line);
}
return responseBody.toString();
} catch (IOException e) {
throw new RuntimeException("API 응답을 읽는데 실패했습니다.", e);
}
}
검색하면 이런식으로 DB에 값이 잘 저장되는 걸 확인할 수 있습니다.
왼쪽 컬럼은 사용자 고유번호여서 신경쓰지 않으셔도 됩니다.

📝 Mapper 클래스
변환된 단어를 기준으로 해서 중복된 값이 저장되지 않도록
매퍼(Mapper)는 아래와 같이 작성했습니다.
@Insert("INSERT INTO VOCA (CRID, UNUM, WORD, RESULTWORD) " +
"SELECT #{crid}, #{unum}, #{word}, #{resultWord} " +
"FROM dual " +
"WHERE NOT EXISTS (" +
" SELECT 1 " +
" FROM VOCA " +
" WHERE CRID = #{crid} AND UNUM = #{unum} AND RESULTWORD = #{resultWord}" +
")")
int save(VocaDto vocaDto);
처음에는 변환할 텍스트 값인 word를 기준으로 해서
중복값이 저장되지 않도록 했었는데, 공백을 구분하지 못하더라고요.
예를들어, "사용할 수 없는"을 입력했을 때 DB에 "unfit for use"가 저장되는데
"사용할수없는"을 입력했을 때에도 "unfit for use"가 저장되더라고요.
그래서 변환할 텍스트인 word가 아닌 변환된 텍스트인 resultword를 기준으로 잡아
중복값이 저장되지 않도록 했습니다.
'2023-02 몰입형 SW 정규 교육' 카테고리의 다른 글
| [Spring] 이클립스(eclipse) annotation 사용하여 객체 주입 (2) | 2023.10.24 |
|---|---|
| [Spring] 이클립스(eclipse) XML 기반 세터/생성자 주입 (setter/constructor) (1) | 2023.10.23 |
| [Spring] 이클립스(eclipse) 자바 스프링 프로젝트 생성 방법 (0) | 2023.10.23 |
| [Vue] VS Code에 Vue 프로젝트 생성 (0) | 2023.09.22 |
| HTTP 상태 코드 100 ~ 500 (0) | 2023.09.21 |